Method
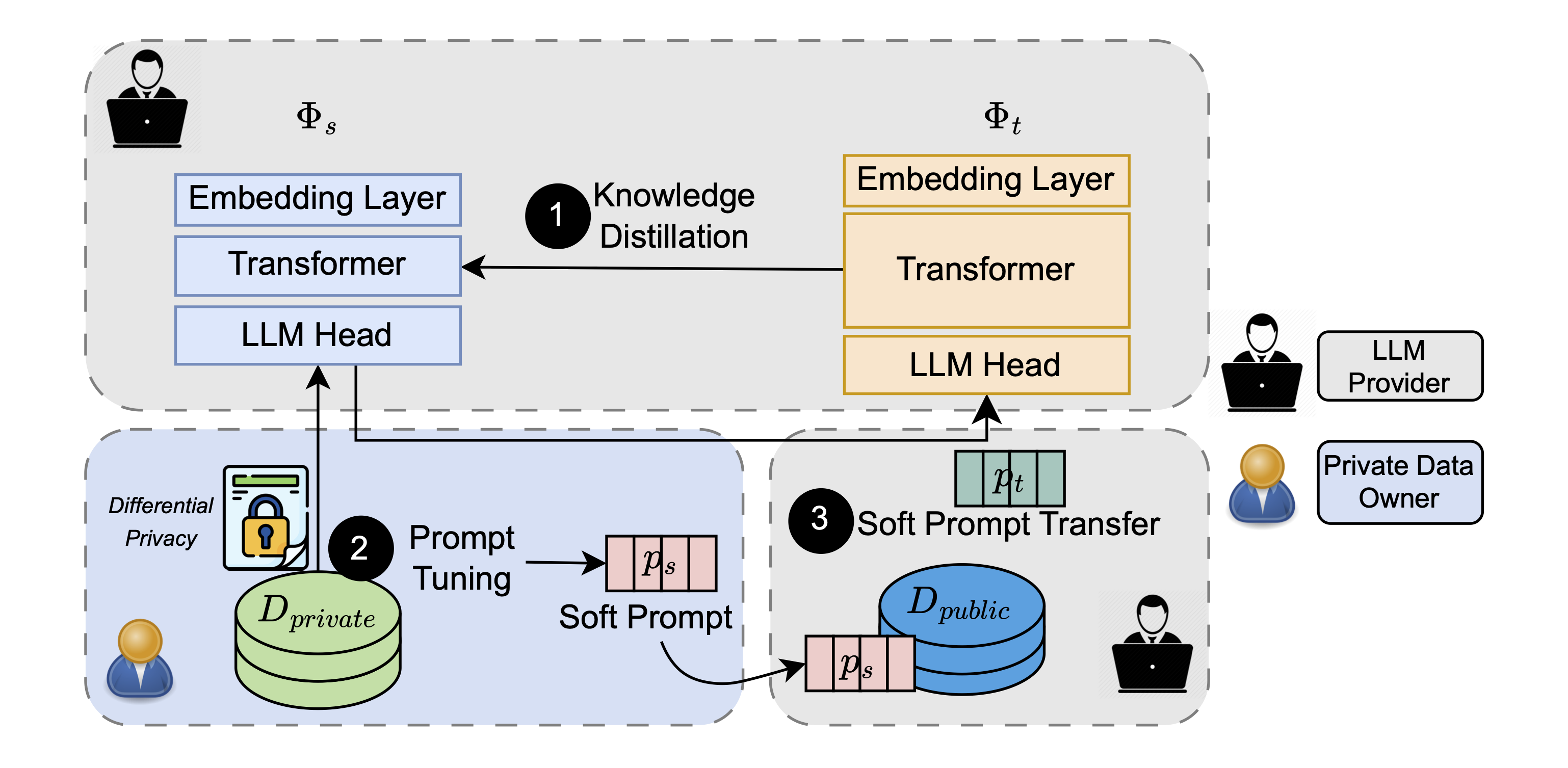
Method overview for POST. 1 An LLM provider compresses their LLM $\Phi_t$ into a smaller model $\Phi_s$ through knowledge distillation. 2 The private data owner learns a specific soft prompt $p_s$ on $\Phi_s$ using the private dataset (optionally with differential privacy guarantees). 3 The LLM provider obtains the soft prompt $p_t$ for solving the user's task by transferring $p_s$ to the target LLM $\Phi_t$—solely relying on a small public dataset and no access to the private data for transfer.
1 Knowledge Distillation
We peform KD to compress the big LLM from model provider to a small model. The distillation objective is given by the the formula below.
This objective combines three losses: distillation loss \( \mathcal{L}_{\mathrm{ce}} \) , language modeling loss \( \mathcal{L}_{\mathrm{lm}} \) ,and embedding cosine loss \( \mathcal{L}_{\mathrm{cos}} \) . The distillation loss \( \mathcal{L}_{\mathrm{ce}} \) measures the Kullback-Leibler divergence between the logits of $\Phi_s$ and $\Phi_t$. The language modeling loss \( \mathcal{L}_{\mathrm{lm}} \) corresponds to the standard pretraining objective, using cross-entropy to predict masked or next tokens. The embedding cosine loss \( \mathcal{L}_{\mathrm{cos}} \) computes the cosine distance between the embeddings of $\Phi_s$ and $\Phi_t$. These three losses are weighted by $\alpha_{ce}$, $\alpha_{lm}$, and $\alpha_{cos}$ .
We perform an aggressive KD that does not take the student performance into account, but compresses the model to the maximum. This has the purpose of ensuring that $\Phi_s$ is small enough to fit into the user’s hardware for local prompt tuning and is not performant enough to disincentivise the (paid) use of $\Phi_t$, as desired by the LLM provider. We show the model size before and after KD in the table below.
| Model | Layer Number | Parameter Num (M) |
|---|---|---|
| Roberta-base | 12 | 125 |
| Our distilled Roberta-base | 2 | 53 |
| GPT2-XL | 48 | 1560 |
| Our distilled GPT2-XL | 4 | 205 |
| Llama2-7b | 32 | 6738 |
| Our distilled Llama2-b | 2 | 667 |
2 Local Prompt Tuning
In this step, users locally tune a source prompt \(p_s\) on the small source model $\Phi_s$ using their private data \(D_{\text{private}}\) .
This provides confidentiality for the private data since the data is not directly sent to the LLM provider. Besides, we also propose to tune \(p_s\) with DP, for example, using the PromptDPSGD algorithm (Duan et al., 2023a). This ensures that the learned prompts also have a formal privacy guarantee.
3 Prompt Transfer with Public Data
We propose to use a small \(D_{\text{public}}\) to transfer the source prompt \(p_s\) on $\Phi_s$ to the target prompt \(p_t\), that can be used on $\Phi_t$ .
We design a loss function for such transfer.
\(\mathcal{L}_1\): align the predictions of the prompted source and target models.
\(\mathcal{L}_2\): align the direction change induced by the private prompt between \(\Phi_t\) and \(\Phi_s\).
\(\alpha\): control the balance between the two losses.
Experimental Results
Transfer Performnace
We compare the performance of POST agains 4 baselines.
- Full PT: prompt tuning peformance on the full model (upper bound).
- Full ZS: zero-shot performance of the full model.
- Compressed PT: prompt tuning performance on the compressed model.
- Direct Transfer: directly apply the soft prompt to large model.
Confidential Transfer of Llama2-7B
Confidential and DP (ε=8) Transfer of Llama2-7B
The results show that:
- POST outperforms full model ZS, compressed model PT, and direct transfer.
- POST achieves close performance to the full model PT.
- POST performs well with and without DP.
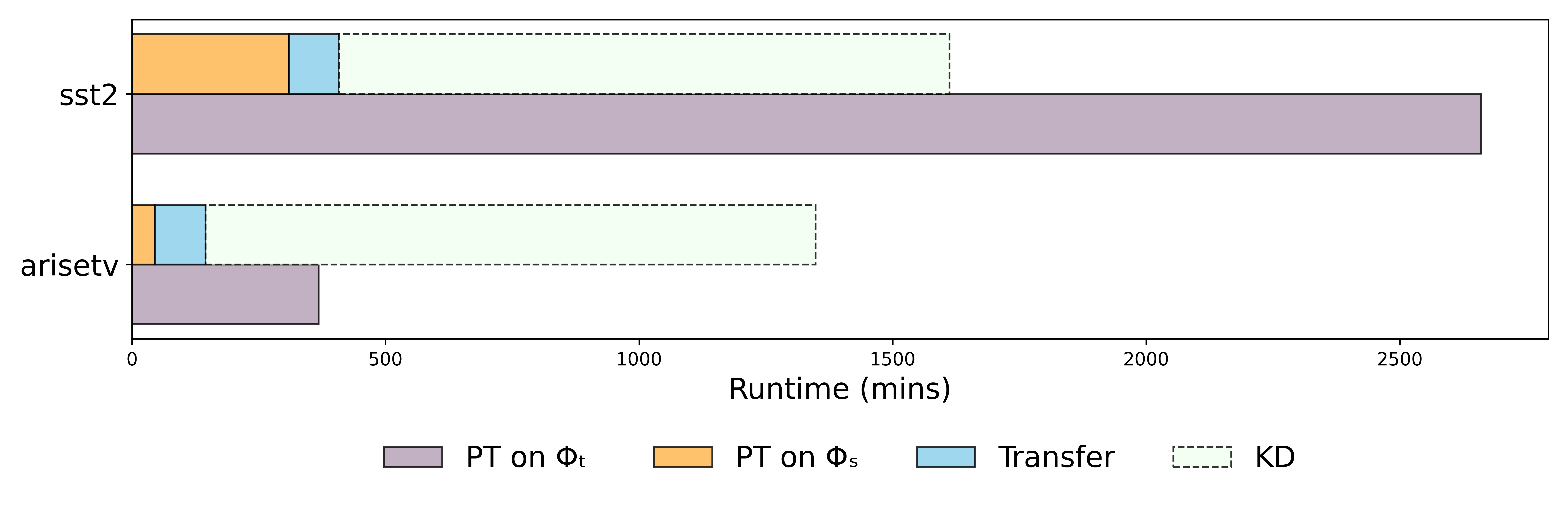
Runtime Performnace
We analyze the runtime of our POST’s individual components and compare them to the runtime of full prompt tuning on GPT2-XL. Note that in practice, full prompt tuning on the large LLM leaks all the private prompt data to the LLM owner and is, hence, not practical. POST exhibits a significant sppedup in runtime compared to full prompt tuning on the large LLM.
Baseline Comparison
We compare POST with the following prompt transfer methods:
- Zero-shot Transfer (Wu et al., 2023) : tune the soft prompt on the large model using the private data.
- DP-OPT (Hong et al., 2023) : tunes a discrete prompt locally and then directly uses it on the large model.
We compare the performance of POST against these baselines on 7 datasets. The experiments use Llama2-7B model as target model, each method are evaluated with and without DP. The results are shown in the table below.
| Method | $\Phi_s$ | sst2 | imdb | tweet | arisetv | mpqa | disaster |
|---|---|---|---|---|---|---|---|
| OPT | 2-Lay | 81.31 | 68.44 | 38.35 | 82.00 | 58.50 | 46.00 |
| OPT | GPT2 | 81.65 | 79.55 | 43.40 | 78.26 | 77.60 | 55.60 |
| DP-OPT | GPT2 | 72.59 | 69.53 | 24.90 | 30.44 | 61.80 | 48.90 |
| ZST | 2-Lay | 62.38 | 70.57 | 42.80 | 58.33 | 33.31 | 43.55 |
| ZST with DP | 2-Lay | 53.55 | 69.47 | 41.65 | 59.54 | 32.70 | 43.49 |
| POST (ours) | 2-Lay | 90.14 | 86.27 | 61.70 | 86.71 | 87.37 | 62.84 |
| DP-POST (ours) | 2-Lay | 89.91 | 83.26 | 59.55 | 82.60 | 80.17 | 58.62 |